|
December
7, 2005
Operator-Precedence Parsing
Operator-precedence parsing is a clear and simple approach the task of
writing instructions of a machine to evaluate arithmetic expressions. For
example, an expression such as
(a*a – 3*b*b)^0.5
is parsed using a precedence table for determining what action (shift,
reduce, accept or reject as an error) to take as each symbol is read from
left to right. The precedence table I’ll implement is just a square array
like this
|
|
Input
|
|
opr
|
+
|
*
|
Eos
|
|
+
|
reduce
|
shift
|
reduce
|
|
*
|
reduce
|
reduce
|
reduce
|
|
Eos
|
shift
|
shift
|
accept
|
The operator currently on top of the operator stack is listed in the first
column and determines what row to use for look-up, while the newly
encountered operator is the “input” that determines the column to use.
An excellent and more theoretical treatment may be found in Compilers, Principles, Techniques and Tools, by Aho,
Sethi, and Ullman. The code I based this work on is from Tom Niemann
and is described in these documents:
Let’s
start by looking at the enumerated list of precedence table actions, actEnum:
|
/* actions
*/
typedef enum {
S,
/* shift */
R, /*
reduce */
A, /*
accept */
E1, /*
error: missing right parenthesis */
E2, /*
error: missing operator */
E3, /*
error: unbalanced right parenthesis */
E4 /*
error: invalid function argument */
} actEnum;
|
Essentially,
if the precedence of the next input operator is less than or equal to the
operator on top of the operator stack, reduce, otherwise, shift. The exceptions to this basic tenet are
right parentheses which always cause a reduce() unless there’s an open
parenthesis on the back of the stack, in which case you get a shift(). unless
you’ve come to the end of the expression and the end of the operator stack,
then, if the expression is well formed, you should be left with the final
result on the operand (values) stack and you go into the final “accept”
state. Of course, if the expression is
ill-formed because the parentheses aren’t balanced or there is no operator or
operand where there should be one, then we want to be able to report on the
error.
And
here’s a fairly robust enumerated list of operators that are pushed/popped
on/off the operator stack depending on what symbols (tokens) are extracted
from the expresson, tokEnum: At the end, we also include a token tVal to signal that an operand has
been detected.
|
/* tokens */
typedef enum {
/* operators
*/
tAdd, /* + */
tSub, /* - */
tMul, /* * */
tDiv, /* / */
tPow, /* ^
(power) */
tUmi, /* -
(unary minus) */
tFact, /* f(x):
factorial */
tPerm, /* p(n,r):
permutations, n objects, r at a time */
tComb, /* c(n,r):
combinations, n objects, r at a time */
tComa, /* comma */
tLpr, /* ( */
tRpr, /* ) */
tEos, /* end of
string */
tMaxOp, /* maximum
number of operators */
/* non-ops */
tVal /* value
*/
} tokEnum
tokEnum tok,
prevtok; /*
tokens */
double tokval; /* token
value */
|
Note
the use of tMaxOp, which, as
long as it appears at the end of list of operators can be used as a count for
the number of operators, allowing one to add/subtract from the list without
having to reset this value.
The
variables tok and prevtok will hold the operator token
as it read from the expression string and the previous token currently on the
top of the operator stack.
Now
we define global variables for the vector
of char to hold the characters
of the string and for the stacks holding operators (opr) and operands (val)
as the expression is parsed:
|
#define MAX_OPR 50
#define MAX_VAL 50
#define MaxStr 15
vector<char> vString(MaxStr); /* expression string */
std::vector<char>::iterator vSIter = vString.begin();
vector<char> opr(MAX_OPR); /* operator stack */
vector<double> val(MAX_VAL);/* value stack */
|
vSIter is the iterator for stepping through the
expression string.
Here’s
the look-up table for actions that depend on operator precedence:
|
char parseTbl[tMaxOp][tMaxOp]
= {
/* stk ------------------ input
------------------------ */
/* +
- * /
^ M f
p c ,
( ) $
*/
/* --
-- -- --
-- -- --
-- -- --
-- -- -- */
/* + */ { R,
R, S, S,
S, S, S,
S, S, R,
S, R, R },
/* - */ { R,
R, S, S,
S, S, S,
S, S, R,
S, R, R },
/* * */ { R,
R, R, R,
S, S, S,
S, S, R,
S, R, R },
/* / */ { R,
R, R, R,
S, S, S,
S, S, R,
S, R, R },
/* ^ */ { R,
R, R, R,
S, S, S,
S, S, R,
S, R, R },
/* M */ { R,
R, R, R,
R, S, S,
S, S, R,
S, R, R },
/* f */ { R,
R, R, R,
R, R, R,
R, R, R,
S, R, R },
/* p */ { R,
R, R, R,
R, R, R,
R, R, R,
S, R, R },
/* c */ { R,
R, R, R,
R, R, R,
R, R, R,
S, R, R },
/* , */ { R,
R, R, R,
R, R, R,
R, R, R,
R, R, E4},
/* ( */ { S,
S, S, S,
S, S, S,
S, S, S,
S, S, E1},
/* ) */ { R,
R, R, R,
R, R, E3, E3, E3, R, E2, R, R },
/* $ */ { S,
S, S, S,
S, S, S,
S, S, E4, S,
E3, A }
}; // $ = Eos
|
Note
the error codes: a closed parenthesis followed by an open parenthesis, for
instance, leads to E2: missing operator.
I suppose that at some later date we may want to introduce implicit
multiplication, but it’s disallowed for now.
If the stack is empty and we encounter a closed parenthesis then we
have E3: unbalanced right parenthesis, and so on.
Here’s
the little function that handles error messages: (using some legacy code…what
the heck!) :
|
int error(char *msg) {
printf("error: %s\n",
msg);
return
1;
}
|
The
main function serves mainly to
clear the decks and fetch an expression for parse(). The cout << "\n = " << val[0];
statement reports what is hoped is a successful parse.
|
int main(void) {
another = true;
static char str[MaxStr];
//
static means it retains its value, even when out of scope
while(another) {
//clear the decks
opr.clear();
val.clear();
vString.clear();
//
Input the expression
cout <<
"\nenter expression (0 to quit):\n";
cin >> str;//Do NOT use getline!!!!;
for(int i = 0; i
< strlen(str); ++i) {
//skip over spaces
if(str[i] != ' ') vString.push_back(str[i]);
}
vSIter = vString.begin();
parse();
printVector(val);
}
return
0;
}
|
There’s
certainly plenty of room for improvement here. It took me an embarrassingly long time to
realize that getline() sometimes skips the last character!! Argh!!!!!
No doubt, I’ll find further troubles.
The
parse() function below loads
the operator stack with a tEos
token so that when it meets it at the end it can tell whether or not it has
completed successfully. Then gettok() is called for the first
time with firsttok set to true
so that prevtok will be
initialized to tEos.
|
int parse() {
/* initialize for next expression
*/
opr.push_back(tEos); // also if no recognized char
firsttok = true; // firsttok is
global
if (gettok()) return 1; //if gettok
fails, abort
/* scan
symbols into ? */
while(1) {
/* input
is value so accumulate digits until not a value */
if (tok == tVal) {
/* shift token to value
stack */
if
(shift()) return 1;
continue;
}
/* input
is operator */
switch(parseTbl[opr.back()][tok]) { //[oprTop]][tok]) {
case
R:
if (reduce()) return 1;
break;
case
S:
if
(shift()) return 1;
break;
case
A:
/*
accept */
if (val.size() != 1) return error("syntax error");
return
0;
case
E1:
return
error("missing right parenthesis");
case
E2:
return
error("missing operator");
case
E3:
return
error("unbalanced right parenthesis");
case
E4:
return
error("invalid function argument");
} //end
switch
}//end while
}//end parse
|
Here’s
gettok(), which, as mentioned
above, first checks to see if it’s the first token and if it is, initializes prevtok to tEos. Also, if
at the end of the string, set tok
to tEos—this establishes the
conditions for achieving success in the form: when both tok and prevtok are tEos. If the token is a digit then we set about
accumulating it and subsequent digits or a decimal point into tempval[], by, tempval[i++] = *vSIter and which is then converted to a double by atof(). Finally, check for the unary minus operator
tUmi and reset prevtok.
|
/////////////////////////////////////////////////////////////
int gettok() {
if (firsttok) {
firsttok = false;
//it's not true anymore!
prevtok = tEos; // end of
string token
}
if(vString.size() == 1 && vString[0] ==
'0') {
another = 0; // return to main
for another expression
return 1;
}
if (vSIter != vString.end()) { //not at end of expression
switch (*vSIter) {
case '+': {
tok = tAdd; //In each, set
appropriate token
++vSIter; // and increment global counter
break; }
case '-': {
tok = tSub;
++vSIter;
break; }
case '*': {
tok = tMul;
++vSIter;
break; }
case '/': {
tok = tDiv; //opr.push_back(tDiv);
++vSIter;//*str++;
break; }
case '^': {
tok = tPow; //opr.push_back(tPow);
++vSIter;//*str++;
break; }
case '(': {
tok = tLpr; //opr.push_back(tLpr);
++vSIter;//*str++;
break; }
case ')': {
tok = tRpr; //opr.push_back(tRpr);
++vSIter;//if(nestLevel == 0)
break; }
default:
//Convert the number characters
into a floating point number
//Floats can have 7 digits of
precision, but we will allow the
// user to input as much as they
want.
//First, check to make sure that
it is indeed a number
if
(!isdigit(*vSIter)) {
cout << "\nunknown command\n";
return false;
}
tok = tVal;
char tempval[MaxStr];
int i = 0;
for( ;
vSIter!=vString.end()
&& (isdigit(*vSIter)
|| *vSIter ==
'.');++vSIter) {
tempval[i++] = *vSIter;
}//end for
tempval[i] = '\0'; //need
this for atof
tokval = atof(tempval);
//convert string to float
} // end switch (no scientic notation power of 10?)
}
else { // at end of
expression to…tag it
tok = tEos;
}
/* check for
unary minus */
if (tok
== tSub) {
if
(prevtok != tVal && prevtok != tRpr) {
tok = tUmi;
}
}
cout << "\nprevtok = "
<< prevtok;
prevtok = tok;
cout << "\n";//tok = " << tok;
return
0;
}
|
In
the infinite while(1) loop of parse(), we first check to see if tok is an operand token, tVal, and, if so, use shift() to put it on the operand
stack, val. When shift()
completes successfully, it not only returns a 0 (meaning that we’ll skip the
remaining commands in the while(1)
loop and continue to do it
again) but it will also call gettok()
to set the next tok value. It is key
to note here that shift calls gettok
|
if (tok == tVal) {
/* shift token to value stack */
if
(shift()) return 1;
continue;
}
|
If the
token is an operator then we compair it with the last operator (currently on
top of the operator stack, opr) and
use the look-up table, partTbl[][] to determine whether we should shift(), reduce(), accept (be done) or deliver some error
message:
|
/* input is
operator */
switch(parseTbl[opr.back()][tok])
{ //follow precedence
case R:
if (reduce()) return 1;
break;
case S:
if
(shift()) return 1;
break;
case A:
/* accept
*/
if
(val.size() != 1) return error("syntax
error");
return
0;
case E1:
return
error("missing right parenthesis");
case E2:
return
error("missing operator");
case E3:
return
error("unbalanced right parenthesis");
case E4:
return
error("invalid function argument");
}
|
The
shift() function is fairly
simple—it either pushes the global tokval
(set in gettok()) on the
operand stack, val, or it
pushes an operator token tok
on the operator stack, opr. It then gets the next token with a gettok():
|
int shift(void) {
if (tok
== tVal) {
val.push_back(tokval);
} else {
opr.push_back((char)(tok));
}
//get next token
if
(gettok()) return 1;
// successful:
cout << "\nAfter shift, opr =
"; printOpr(opr);
cout << "\nAfter shift, val =
"; printVector(val);
return
0;
}
|
Reduce
is a little longer: besides many more kinds of tokens to consider, it needs
to do the computations and keep track of stack management maneuvers. The simple binary operations: ambition,
distraction, derision and uglification are fairly straight forward: replace
the next to last element on the operand stack with the result of the
operation and then pop off the last value, making the result the last value. Unary minus is simplest: negate the value
on top (val.back() = -val.back()). The factorial, combination and permutation
operations are thrown in for good measure: but most enigmatic, perhaps, is tRpr. All it does is pop itself off again. What’s going on, you might ask? As I have—leading to a little bald spot
developing on the back of my noggin.
The key to understanding this is to note that reduce() does not push
anything on the stack, though it will pop things off. So tok
may continue to equal tRpr
through many parse table lookups until all operations inside the pair of
open/close parentheses are done, eventually leading to the parseTable((,)) lookup, which says to shift()! So,
finally, ‘)’ is pushed on opr, causing a call to parseTable(),?) which can only be a reduce()
or some kind of error, and this causes both the close and the preceding open
parenthesis to be popped off the opr
stack. Pretty nifty, I think, no?
|
int reduce(void) {
// check what
operation is and reduce accordingly
switch(opr.back()) {
case
tAdd:
if (val.empty()) return error("syntax error");
val[val.size()-2] += val.back(); //sum
of last 2 on val stack
val.pop_back(); // get rid of the last one
break;
case
tSub:
if
(val.empty()) return error("syntax
error");
val[val.size()-2] -= val.back();
val.pop_back();;
break;
case
tMul:
if
(val.empty()) return error("syntax
error");
val[val.size()-2] *= val.back();
val.pop_back();
break;
case tDiv:
if
(val.empty()) return error("syntax
error");
val[val.size()-2] /= val.back();
val.pop_back();
break;
case
tUmi:
if
(val.empty()) return error("syntax
error");
val.back() = -val.back();
break;
case
tPow:
if
(val.empty()) return error("syntax
error");
val[val.size()-2] =
pow(val[val.size()-2], val.back());
val.pop_back();
break;
case
tFact:
if
(val.empty()) return error("syntax
error");
val.back() = fact(val.back());
break;
case
tPerm:
if
(val.empty()) return error("syntax
error");
val[val.size()-2] =
fact(val[val.size()-1])
/fact(val[val.size()-2]-val.back());
val.pop_back();;
break;
case
tComb:
if
(val.empty()) return error("syntax
error");
val[val.size()-2] =
fact(val[val.size()-2])/
(fact(val.back()) *
fact(val[val.size()-2]-val.back()));
val.pop_back();
break;
case
tRpr:
/* pop ()
off stack */
opr.pop_back();
break;
}
opr.pop_back();
cout << "\nIn reduce val =
"; printVector(val);
cout << "\nIn reduce opr =
"; printOpr(opr);
cout << "\ntok = "
<< tok;
return
0;
}
|
Before
looking at an example, here’s a flow chart for the algorithm that may help
show what’s happening:
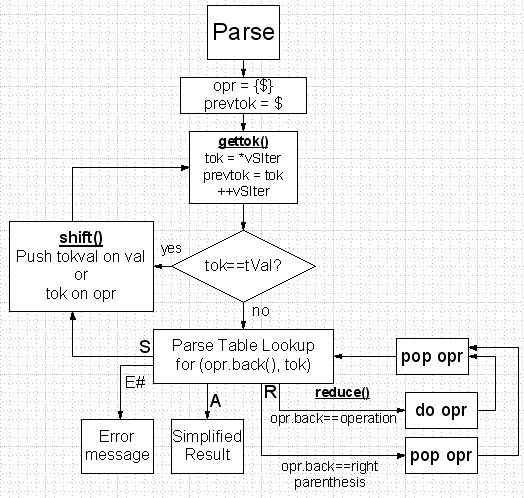
Let’s
look at an example. In response to the
prompt, say we enter
enter expression (0 to quit):
1+(2*3+4)
To
verify that the string has been properly transferred to the vector of
characters, the program announces,
Before parse, string = 1 + ( 2 * 3 + 4 )
Then
gettok() reports it has set pretok, I guess just in case it’s
the only one.
prevtok = 12
Then
gettok() announces the first
value token (1) has been found:
prevtok = 14
…and
shifts it, leaving the opr and
val stacks like so:
After shift, opr = $
After shift, val = 1
Now
shift() calls gettok(), which finds a + operator
prevtok = 0
…which
is shifted onto the opr stack:
After shift, opr = $+
A
left parenthesis operator ( is
encountered and shifted onto the opr
stack:
After shift, opr = $+(
This
continues until we have:
After shift, opr = $+(*
After shift, val = 1 2 3
At
this stage we have a tok = +
operator and since parseTbl(*,+) = R, we reduce, leading to
After reduce, opr = $+(
After reduce, val = 1 6
Now
we look up parseTbl((,+) = S, followed by the value 4,
yielding
After shift, opr = $+(+
After shift, val = 1 6 4
At
last we encounter tok = ),
leading to parseTbl(+,)) => reduction to
After reduce, opr = $+(
After reduce, val = 1 10
And
then the only way a tok = ) can lead
to a shift, parseTbl((,)) = S yields
After shift, opr = $+()
After shift, val = 1 10
...whence the parseTbl(),$) = R calls reduce() to yield two opr pops:
After reduce, opr = $+
After reduce, val = 1 10
…and
the penultimate lookup: parseTbl(+,$) = R for
After reduce, opr = $
After reduce, val = 11
…and
finally, parseTbl($,$) = A allows us to accept the
simplified result,
1 + ( 2 * 3 + 4 ) = 11
|